Beating GPT-4 with Open Source
A bit more than a week ago we posted on X that we had successfully beaten the best performing GPT-4 model at a task that OpenAI essentially invented: function calling. Here you can see the results for yourself:
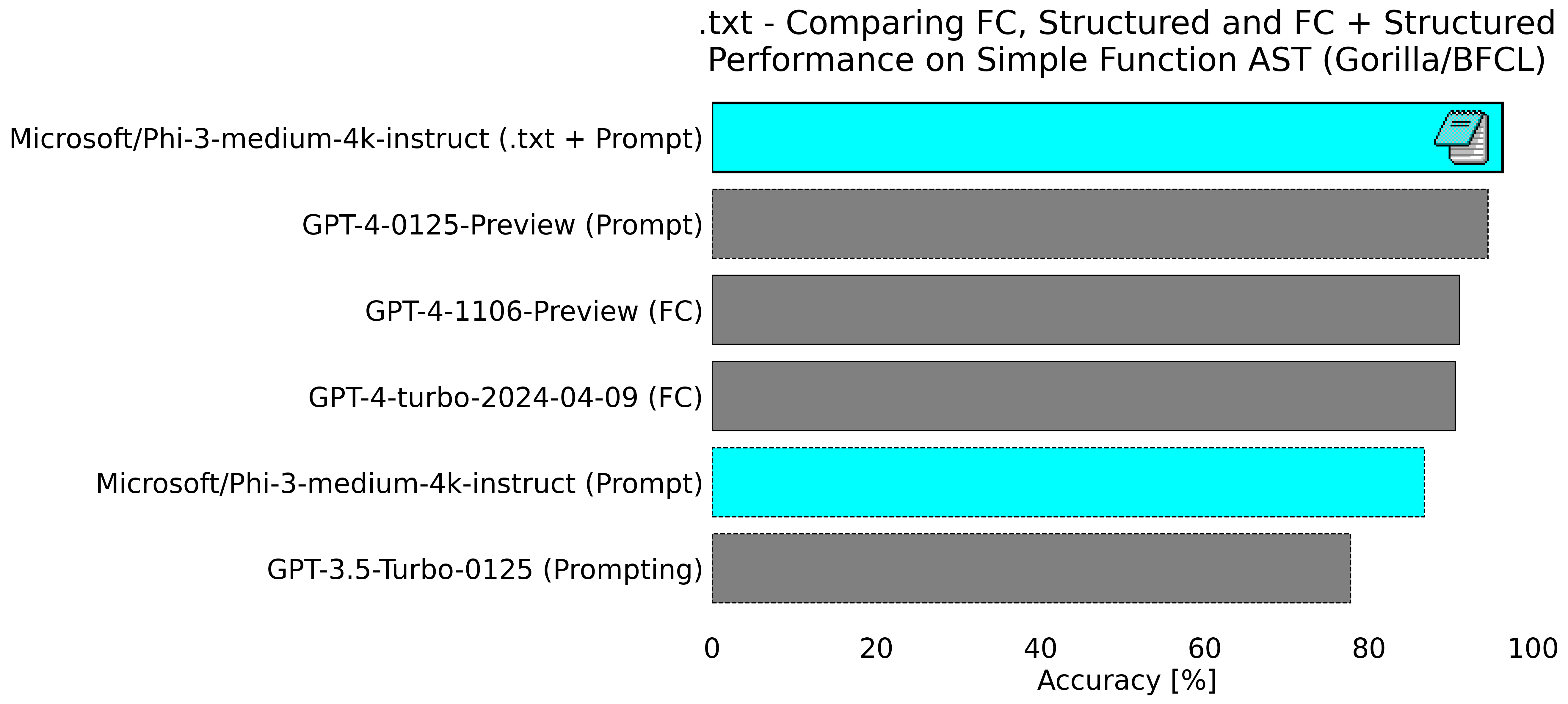
By combining Outlines' structured generation with Microsoft's open LLM, Phi-3-medium, we were able to achieve a score of 96.25% accuracy on the 'simple' function calling task compared to GPT-4-0125-Preview achieving 94.5%
While this is an achievement that we’re incredibly proud of we wanted to focus in this post on the wide range community and open source projects that make this work possible. More than a success for .txt and Outlines, this is an example of the power of the open model community as a whole.
Background
Before diving in there's some basic background we need to cover regarding what "function calling" and "structured generation" are, and introduce the Berkeley Function Calling Leaderboard.
Function Calling
In June 2023, OpenAI announced that they were going to add support for “function calling capabilities” in their API. Function calling has since become a common interface to the LLM where the user provides a list of one or more “functions” and accompanying arguments for that function. The model can then choose to call a function and provide the necessary arguments.
Here is an example from the evaluation set showing how a function calling works. Here is a function called calculate_triangle_area:
{
"function": {
"name": "calculate_triangle_area",
"description": "Calculate the area of a triangle given its base and height.",
"parameters": {
"type": "dict",
"properties": {
"base": {
"type": "integer",
"description": "The base of the triangle."
},
"height": {
"type": "integer",
"description": "The height of the triangle."
},
"unit": {
"type": "string",
"description": "The unit of measure (defaults to 'units' if not specified)"
}
},
"required": [
"base",
"height"
]
}
}
}
As we can see the model now has access to a function it can “call” (really it just returns the function name and argument values, nothing ‘happens’ during function calling).
The function, calculate_triangle_area has two required arguments (base and height) and an optional third argument (unit).
When prompted with a question such as:
"Find the area of a triangle with a base of 10 units and height of 5 units."
The model can “call” the function by replying with a response like this:
"[calculate_triangle_area(base=10, height=5)]"
The main benefit of function calling is that we have a reliable method for having an LLM communicate with other systems and provide a formatted response. It’s easy to image this code being transformed into an actual function call in a language like Python or turned into a request to an API endpoint.
However within the context of LLMs "function calling" is essentially an ad hoc method for structured generation, it simply helps ensure (but does not guarantee, like true structured generation does) that the response from the model adheres to a desired format.
Structured Generation
While it's something we here at .txt think about constantly, it's worth taking a quick moment to talk about structured generation and how it compares with function calling. Structured generation is simply controlling the output generated by an LLM by only allowing the model to sample tokens that adhere to a user defined format. Consider the last example where we want the model to repond in a format of the function call like this:
[calculate_triangle_area(base=<INT>, height=<INT>)]
We can solve this with structured generation by defining a regex that matches this format.
Here is an example of what that regex might look like:
fc_regex = r'[calculate_triangle_area(base=[0-9]{1,3}, height=[0-9]{1,3})]'
When using Outlines for structured generation, this regex can be used to guarantee that the model only produces output matching this format. This provides a much stronger promise about the output format than using the function calling interface to a model does.
There are many other ways we could decide to structure the output using Outlines. We might, for example, want to have the function call be output in JSON, or as YAML if we thought that might be preferred. You can visit the Outlines repository for more detailed examples.
One might assume that constraining the output in this way could adversely affect the performance of the model on a given task. However, in multiple experiments we have found that structured generation notably improves model performance on many evaluation tasks, and offers other benefits as well. This does not appear to be the case with function calling, as there are multiple cases where GPT-4 models perform worse on function calling tasks when using the function calling interface as opposed to using traditional prompting methods. We will be exploring this in more detail in a future post.
Berkeley Function Calling Leaderboard (BFCL)
Since function-calling has become such a powerful method of interacting with LLMs, Berkeley’s Gorilla team has put together a function-calling leaderboard to rank models on their ability to correctly respond to questions requiring function calls. The example question and function definition in the previous section is taken from the set of evaluations used by BFCL.
The leaderboard ranking is determined by evaluating models on their ability to correctly answer 2,000 function calling questions in different categories. For our experiments we have focused exclusively on the simple test set which contains 400 examples of function calls that only provide the model with a single function (which is a fairly common pattern in practice). The challenge for the model then is to correctly output the right function and fill in the required arguments correctly.
With the basics covered, let's dive into all of the parts of the open source world that made it possible to beat GPT-4 on this benchmark!
Open Source Community
When most people think of “open source” they immediately think about software (or perhaps specific models in the LLM context), but the most powerful part of open source is the people and communities around this software.
Our interest at .txt in the BFCL project started when Outlines community member Alonso Astroza shared some really incredible work he had been doing on Outlines Function Calling Evaluation with the Outlines Discord channel. Alonso found that, by applying a straight-forward approach to structured generation, a range of open models could get radically better performance on the leaderboard. As an example, here’s an image from Alonso’s report showing Meta-Llama-3-8B-Instruct going from 58.73% accuracy to 84.25%
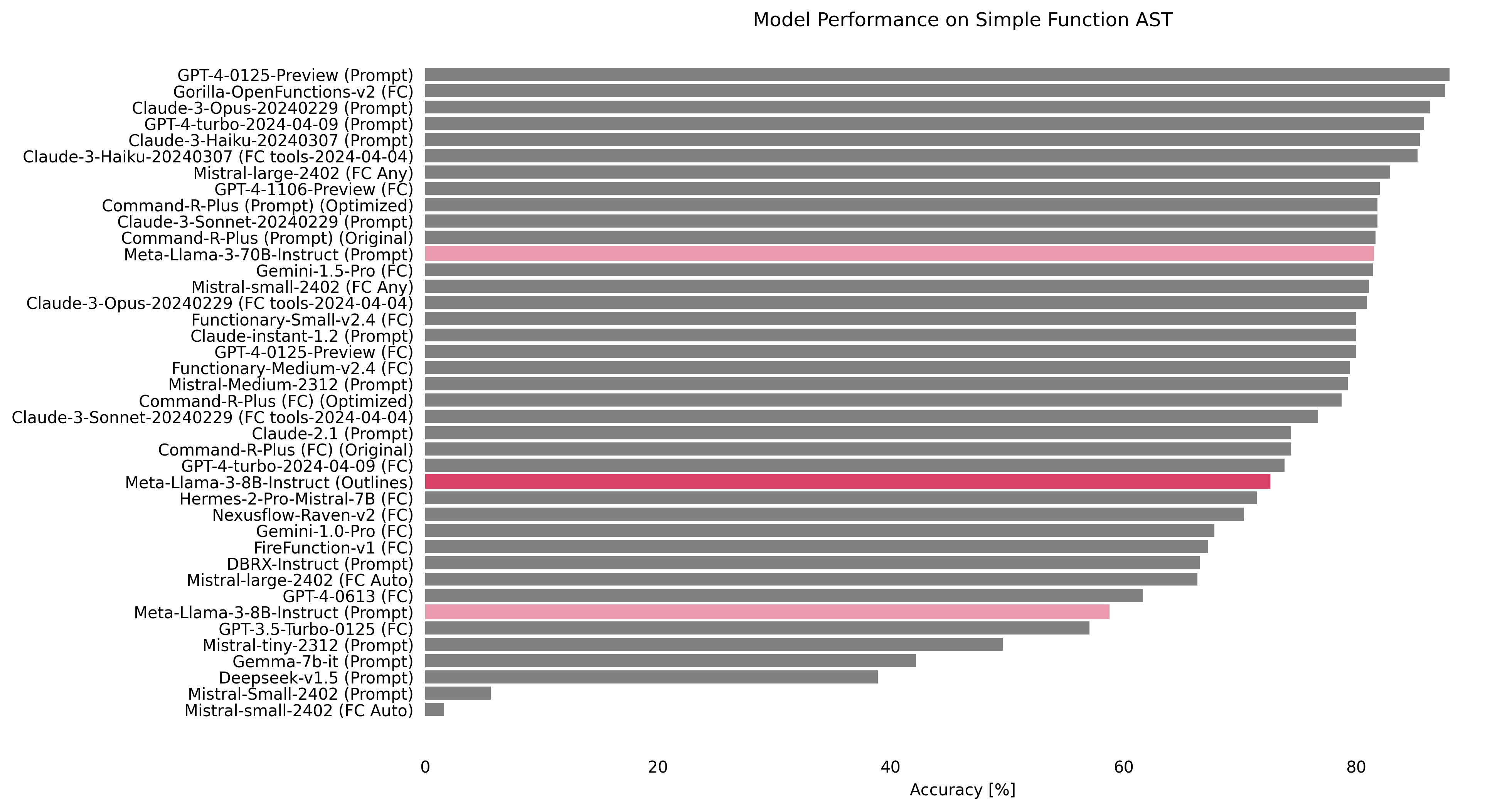
Internally at .txt, we were astounded by these results! Not only did Alonso do this excellent work, but also shared all the code he used for easy reproducibility. This was essential to quickly bootstrapping our internal exploration of this area.
Open Evaluations - Gorilla/BFCL
Alonso’s work was, of course, only possible because the Gorilla team at Berkeley created and, most importantly, shared their the code base for the gorilla/Berkeley Function Calling Leaderboard which was the basis for Alonso’s project.
Making these evaluation open to all is especially important because the details of leaderboards can change quite frequently. As someone who has spent a lot of time trying to reproduce leaderboard results, it can often be impossible without access to the original evaluation setup. You’ve likely noticed that the same evaluation set for the same model will often have different benchmark performances depending on where you see the results posted.
The only way to truly run fair evaluations is to make sure you re-run all evaluations you're interested in yourself to ensure that your best model score is fairly compared to the models you would like to compete against. Notice that in our final run, GPT-4-0125-Preview got 94.5% which is much higher than on the leaderboard website (and actually a bit higher than our original run we shared on X). This is likely from a combination of changes in the way the BFCL evaluations are run as well as internal changes to the GPT-4-0125-Preview model itself allowing for better performance.
In an industry suffering from a bit too much hype, if you want to make any performance claims earnestly, it is necessary to be able to fully reproduce the benchmark. For this reason open source software is vital to communicate about progress in the LLM space across teams.
In the context of open evaluations, it's worth calling attention to the incredible work of the HuggingFace Leadboard and Evaluation research team in explaining the details of many evaluation frameworks, and working to improve the reproducibility of open model evaluation.
Open Models - Mistal-7B and Microsofts Phi-3
Alonso had showed us that we could get dramatically better function calling performance when working with Mistral-7B-v0.2-instruct. By writing a more complex structured approach we were able to further boost the performance of this model. Though the results were impressive it was nowhere near GPT-4 performance.
We then took a look at Mistral-7B-instruct-v0.3 which natively supported function calling. We’ll have much more to say about this in a future post, but as you can see in the figure below, even our best efforts were not quite close enough to beat out GPT-4’s best performing model.
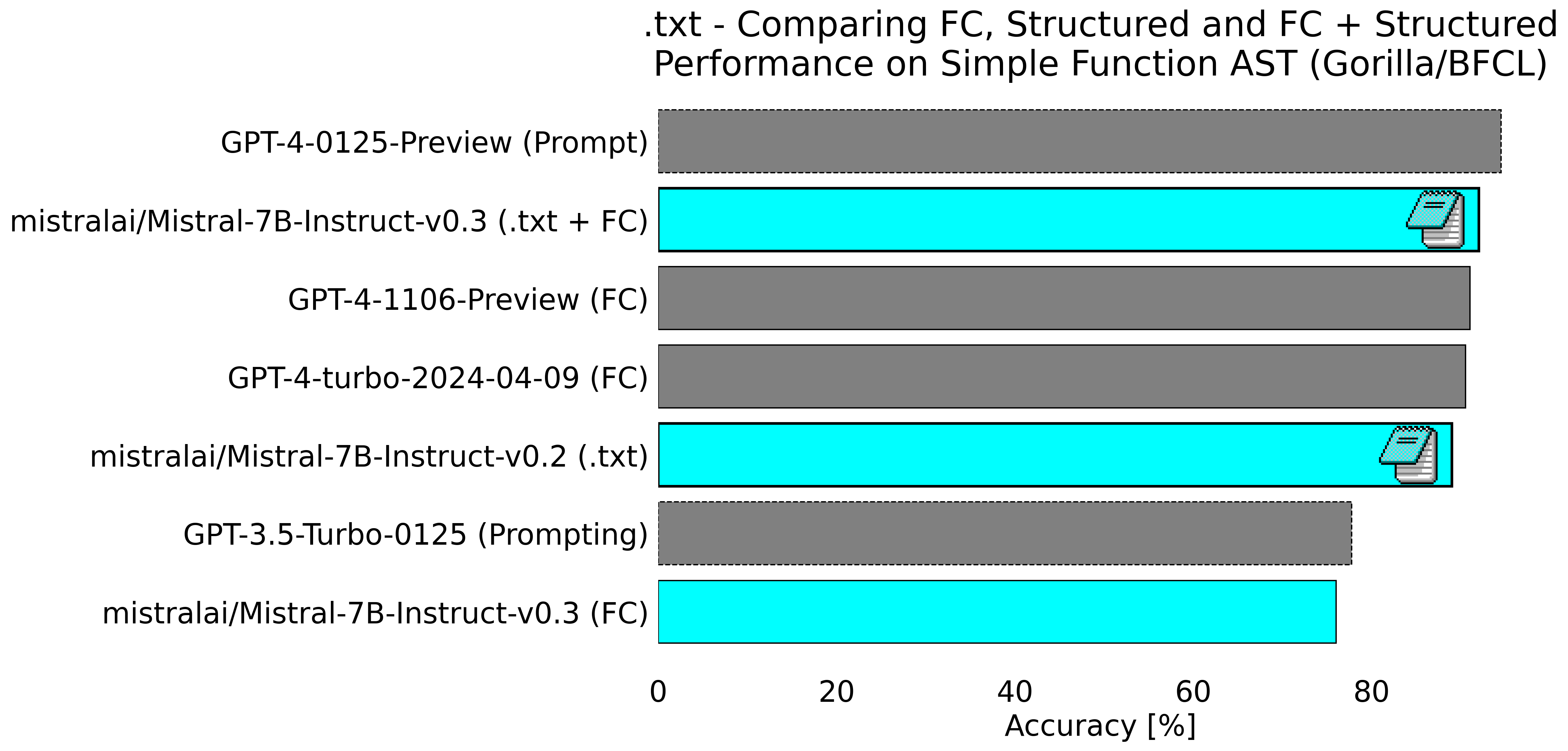
At 92% accuracy for Mistral-7B-Instruct-v0.3 using both native function calling and structured generation we were able to beat out many other versions of GPT-4, but we wanted to beat the highest scoring one.
So we turned to Microsoft’s Phi-3-medium-4k-instruct. We had heard many favorable reports of the model’s performance but were absolutely blown away with its performance once we gave it a try. Without using structured generation the model was very competitive, beating out GPT-3.5 by a substantial margin.
But with structured generation using Outlines, Phi-3 was phenomenal, scoring 96.25% accuracy on the benchmark, beating the best GPT-4 model by a substantial margin!
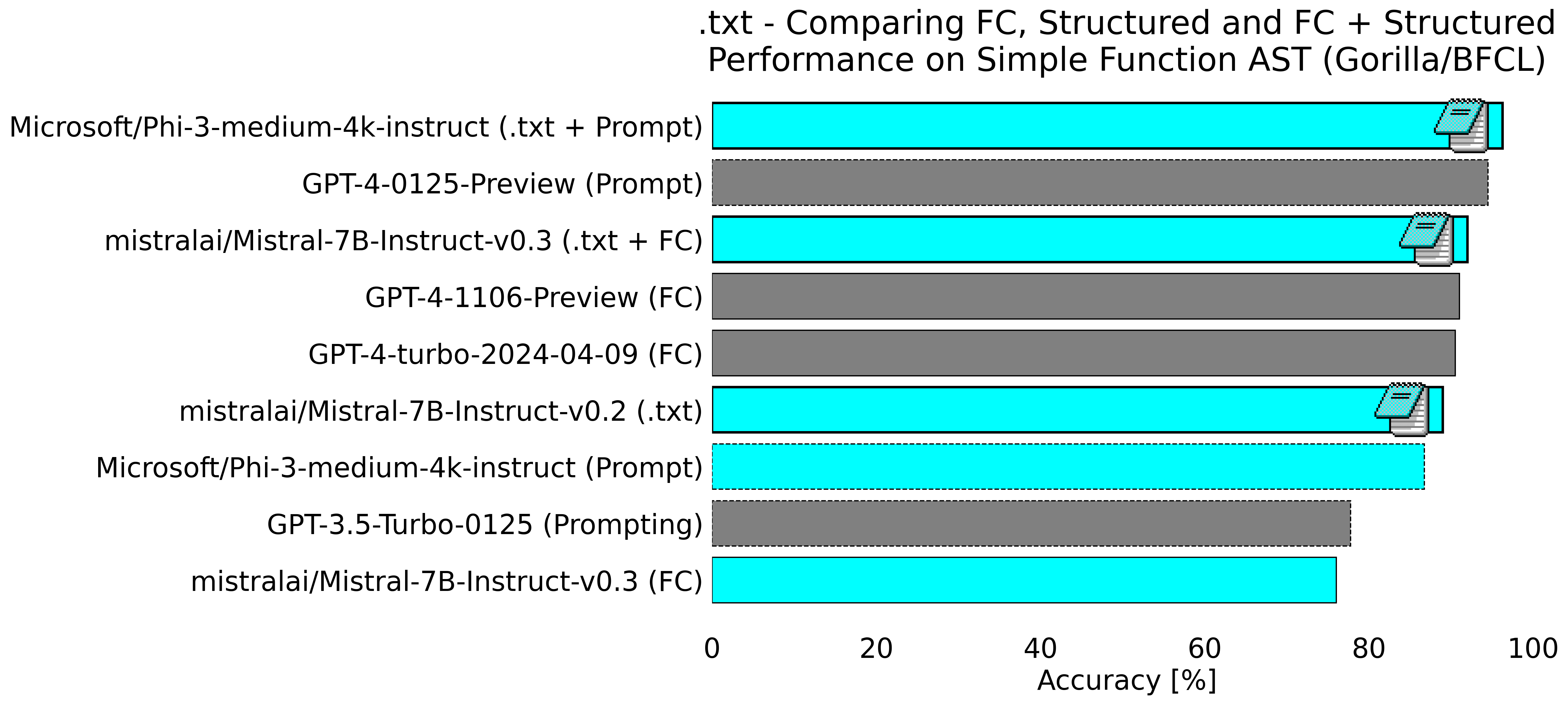
All of our success beating GPT-4 owes a great deal of gratitude to the teams at Mistral and Microsoft who not only created these impressive models, but released them under very open licenses (apache-2.0 and MIT respectively). This means that not only can we use them to show the potential of open models with structured generation, but anyone can use these models + Outlines to get practical results for themselves!
Additionally all of this would not be possible without
HuggingFace not only hosting all these models but making them trivial to work with using their transformers library.
Open Source Tools - Outlines
Outlines is, of course, what ties all this work together and makes it possible for open models to beat even the most powerful priorietary ones!
We’ve been growing very fast and are extremely excited about what’s coming next.
But Outlines is nothing without, not only our community of contributors, but Outlines users of all varieties.
In an upcoming post we'll dive into the details of how exactly we used Outlines for this task and how you too can add function calling capabilities to any open model!
Open Reproducibility
The bow that ties all of this incredible work by so many people together is now we can easily pass this work to you! We’ve forked the gorilla/BFCL library and added all of the code we’ve used to build and run these benchmarks. Rather than just throwing the code in a bucket, we’ve made sure to include ample instruction and supporting code to fully run these evals using Modal for model hosting. For those that just want to explore our results, we’ve included all the data from the experiment and a few notebooks to help you explore further!
Conclusion
We’re quite bullish here at .txt on the future of open models working in collaboration with open source software and the communities around them. OpenAI created the idea of function calling in LLMs and has dominated the BFCL ever since, until now.
What we have shown is that the power of open software allows us to notably exceed OpenAI’s performance. Additionally we’ve been able to bring other models, such as Mistral-v0.3, to a performance tier that, while not beating OpenAI’s best, stands shoulder to should with many of their other proprietary function calling models.
Stay tuned for more posts we have coming up that will dive deeper into how you can use structured generation to get amazing results from your LLM!