Prompt Efficiency - Using Structured Generation to get 8-shot performance from 1-shot.
In this post we’re going to explore a surprising benefit of structured generation that we’ve recently come across here at .txt we call “prompt efficiency”: For few-shot tasks, structured generation with Outlines is able to achieve superior performance in as little as one example than unstructured is with up to 8. Additionally we observed that 1-shot structured performance remains similar to higher shot structured generation, meaning 1-shot is all that is necessary in many cases for high quality performance. This is useful for a variety of practical reasons:
- convenience: For few-shot problems, examples can be difficult to come by and annotating examples that include a “Chain-of-Thought” reasoning step can be very time consuming and challenging.
- speed: Longer prompts mean more computation, so keeping prompt size smaller means faster inference.
- context conservation: Examples easily eat up a lot of context for models with limited context length.
We’ll walk through the experiments we’ve run to show this property of structured generation.
Few Shot Learning with LLMs
“Few Shot” learning refers to the practice of providing the model with several examples of question/reason/answer data from a given benchmark data set in the prompt. Here is an example from the GSM8K task using a “3-shot” prompt:
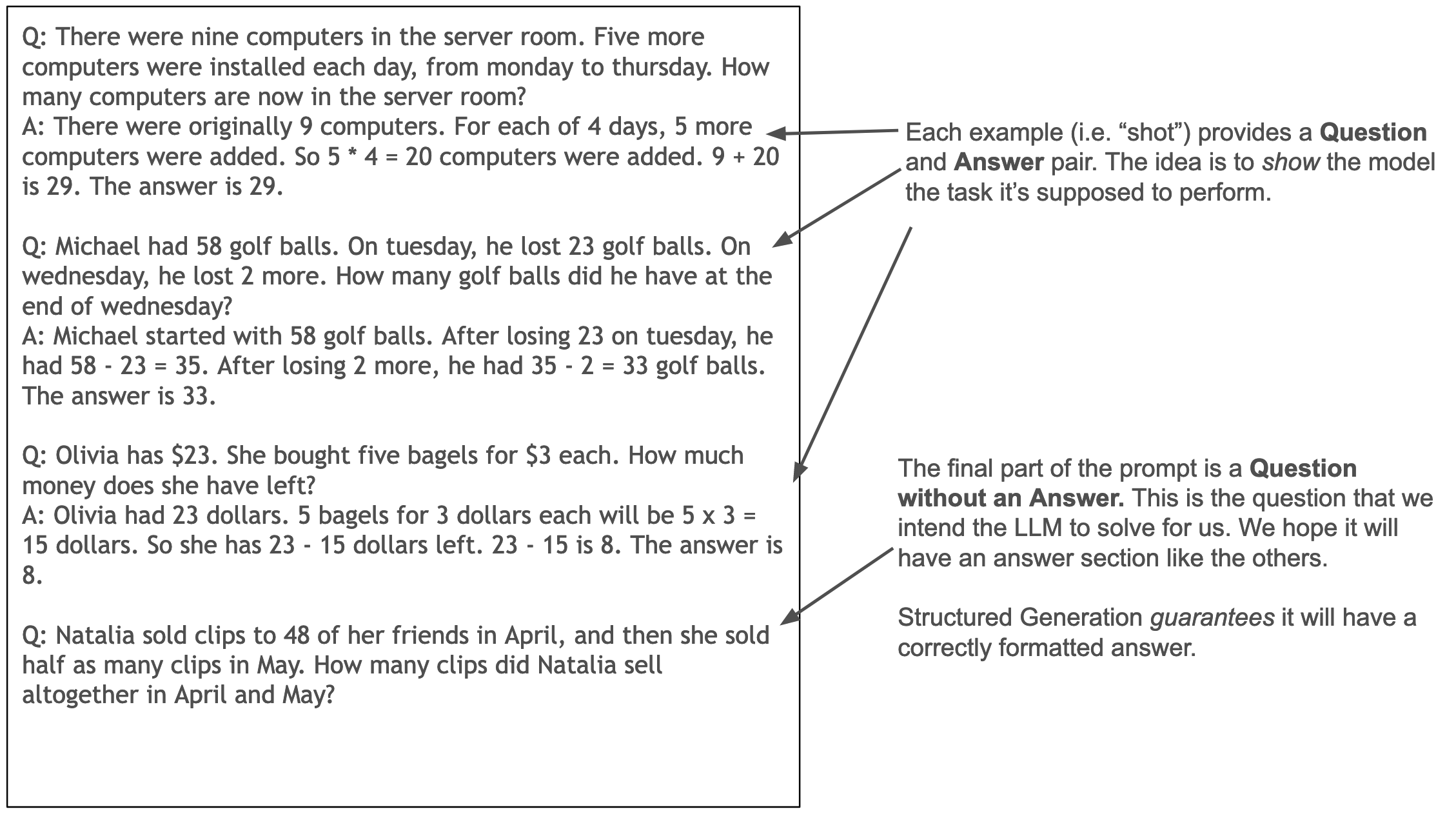
Typically these examples are small in number (nearly always less than 10) compared to traditional machine learning approaches which can easily use thousands to millions of examples to learn the required task.
In nearly all tasks LLMs benefit from being shown a few examples (as opposed to being prompted to complete the task with only instructions, aka 0-shot). While it is incredible that LLMs are able to learn tasks so quickly, it’s also a requirement that LLMs work with few shot cases since limited context length means they can’t process as many examples as traditional machine learning models. Even for models with large (or even potentially unbounded) context lengths, longer context means more time consuming generation.
Prompt Efficiency
While working with Hugging Face’s Leaderboards & Evals research team on an article about prompt consistency, we stumbled across an interesting finding. Not only did structured generation provide better performance something we had explored previously and reduced variance in performance across shots (what we explored with 🤗), but also seemed to dramatically reduce the penalty we observed for 1-shot prompting.
In the image below we can see this in the case of Mistral-7B-v0.1 on the GSM8K data set.
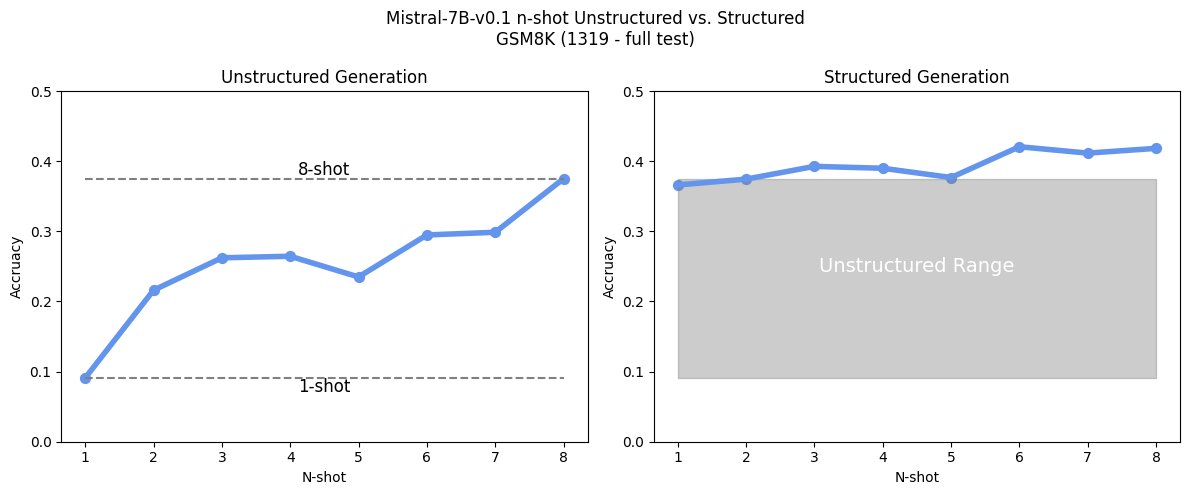
The chart on the left shows the performance across different n-shots for unstructured generation. What we see is that 1-shot performance is abysmal. When looking at chart on the right showing the result for the same n-shots using structured generation we noticed that performance for the 1-shot prompt suffered a much smaller penalty, performing nearly as well as the unstructured 8-shot.
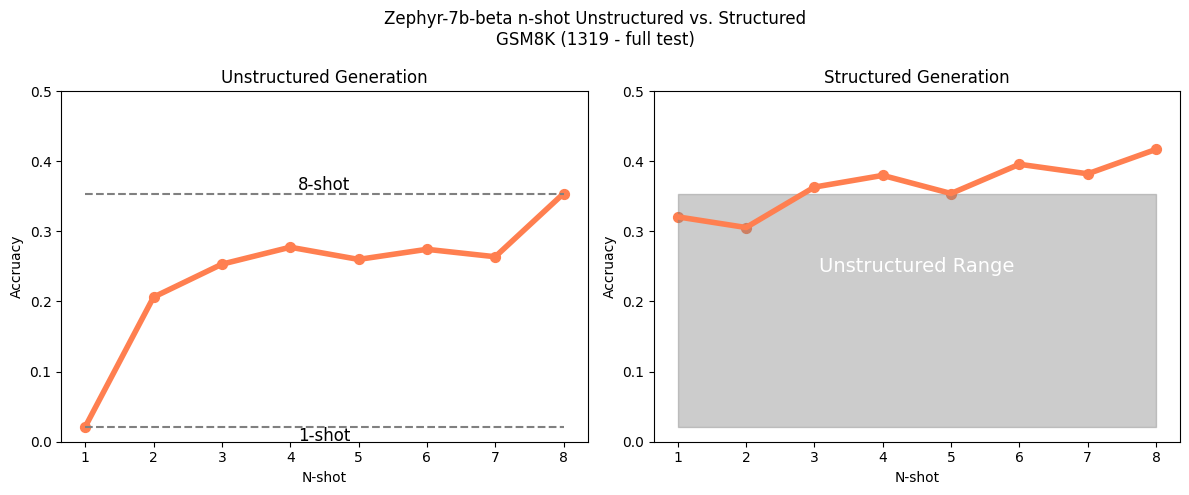
When looking at Zephyr we see an even more dramatic penalty for 1-shot prompting, but once again major improvements when using structured generation:
These results led us to explore the question:
“Can structured generation consistently provide 1-shot performance on par with higher-shot unstructured performance?”
If so, it means you can potentially save a lot of context in your prompt and need far fewer examples to get high quality performance.
To explore this we looked at 6 different models across both the GSM8K evaluation set and the GPQA evaluation set and compared the performance between 1-shot and n-shot performance unstructured with 1-shot performance structured.
GSM8K
The GSM8K data set consists of grade school mathematics questions. The answer to the questions are open response (meaning they are not multiple choice) integers. Here is an example of what an individual “shot” will look like, along with annotations about which parts the model will be responsible for filling in in the end.
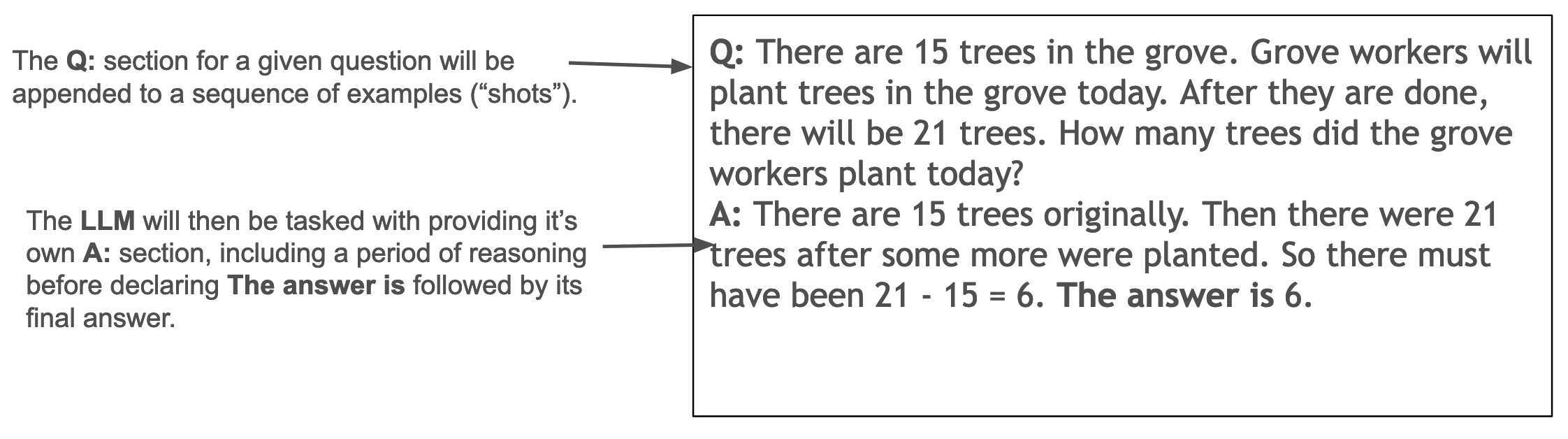
The chart below shows 1-shot and 8-shot performance unstructured, then compares with 1-shot performance using structured generation:
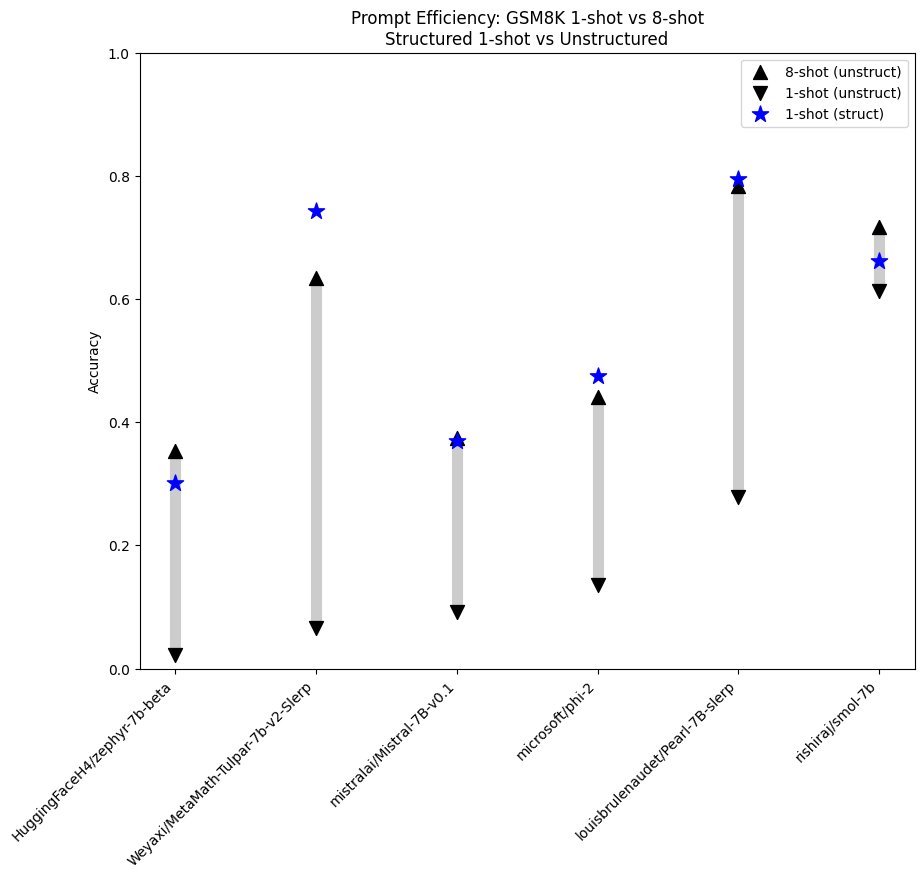
In this chart the blue stars show us the performance of structured 1-shot, while the up and down arrows show us the 8-shot and 1-shot unstructured performance. For example, in the case Pearl-7B-slerp we see that 1-shot unstructured is around 25% accuracy while the 8-shot unstructured performs much better at just shy of 80% accuracy. Looking at the 1-shot structured performance we see that it is just a hair better performing than the 8-shot unstructured! As we can see from this chart, in most cases 1-shot structured generation performs at least as well as 8-shot unstructured generation.
Let’s take a look at a different benchmark and see if these results hold up.
GPQA
The GPQA task is a set of graduate level questions with multiple choice answers. The data set is designed to be “Google-Proof” (that’s what the GP stands for) meaning that, in theory, you cannot easily answer these questions using Google search.
Here is an example question with annotations about each section:
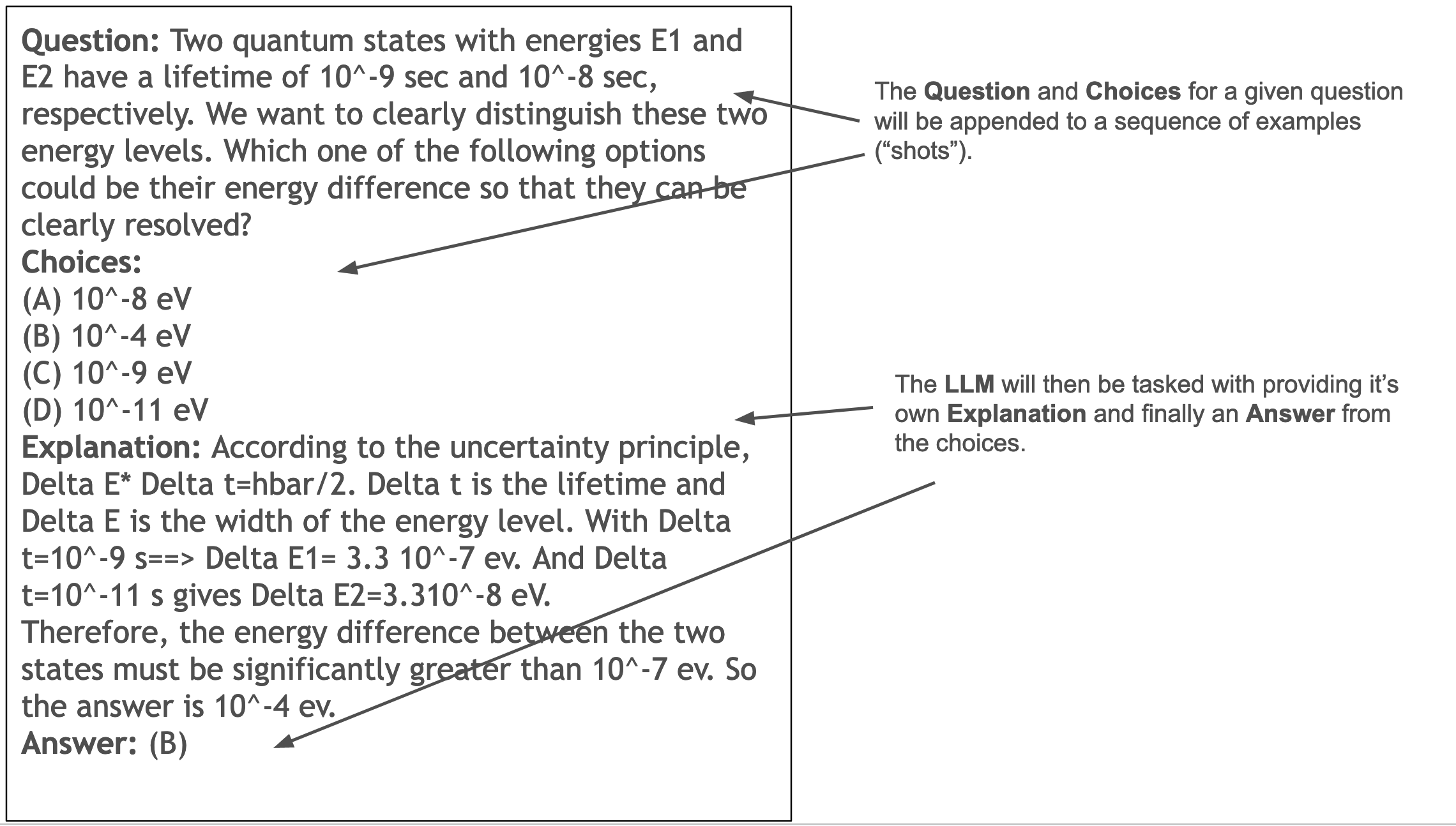
There are two major differences between GPQA and GSM8K. The first is that the questions are notably more difficult, and the second is that the answers are multiple-choice, meaning that the model only needs to select the correct answer of four.
The GPQA model has longer questions and reasoning steps as well as higher variance between different n-shots which lead us to use only up to 5 shots, but rather than comparing just 1-shot to 5-shot we explored all possible shots and compared structured 1-shot to the best-shot for each model on the evaluation. Here are the results.
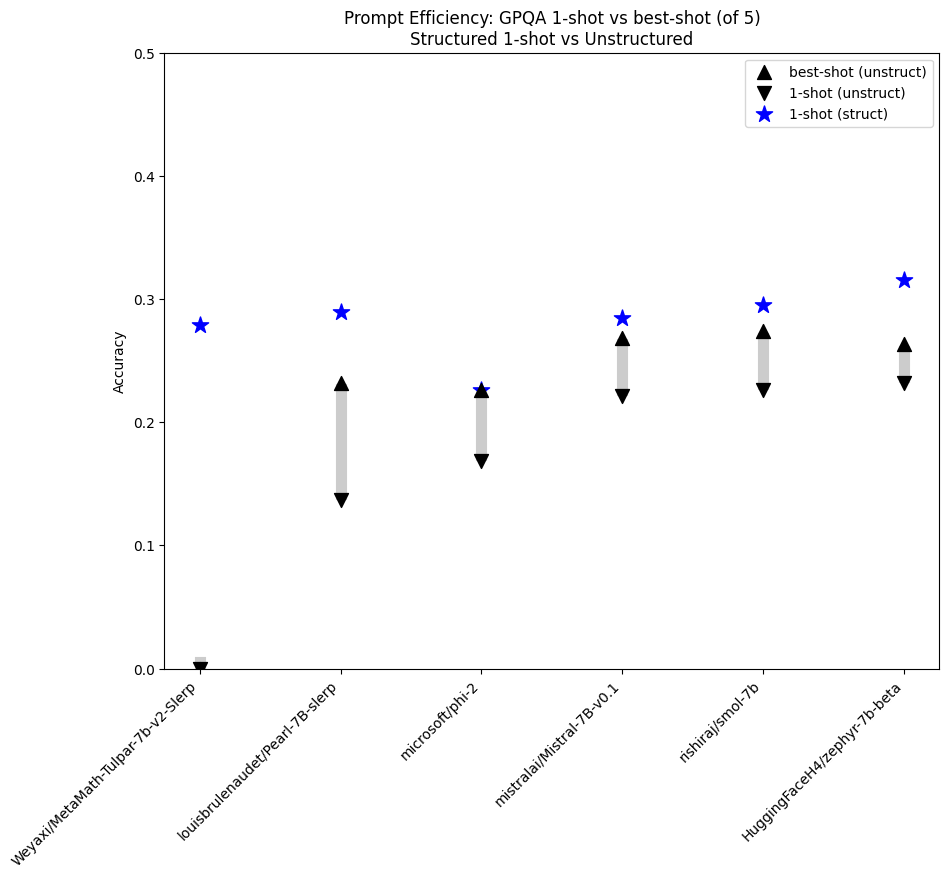
As we can see structured generation provides a major improvement in 1-shot learning. Not only does structured 1-shot consistently match or beat the best performing n-shot, but it is the only case to beat the baseline expectation of a random guess (4 questions meaning you should get 25% by just guessing). This provides evidence that even a single example can be enough to get excellent performance out of a model using structured generation.
What does this tell us about examples in prompts?
For anyone coming from a background in machine learning, it's common to assume that the number of examples provided give the model more semantic information about the problem. That is, by providing examples the LLM will learn better to do the task, similar to how a person might need a few examples of a problem to understand the task. However the fact that structured generation converges to nearly the same performance as other structured n-shots and dramatically out-performs unstructured 1-shot prompts suggests something else might be at work here.
Even though we often think that the power of LLMs is their ability to model the semantics of language, it appears that the structure/syntax is perhaps just as, if not more, important when prompting. It appears that providing additional shots is helping the model to understand the structure of the problem, and providing only 1 example is not enough in most cases. However, when we force the model to adhere to a the required structure it immediately appears to perform well, regardless of the number of shots provided. This suggests that structure alone is doing a fair bit of the work in generating the correct answers.
Our findings here are reminisance of the findings in the Mixtral paper when analyzing the routing of experts. The Mixtral LLM works by having 8 "experts" that the model may chose from when generating tokens. This helps dramatically reduce the total memory required during generation since each expert is only 7B parameters. It was assumed that experts were likely chosen by the model based on the semantic content of the task. However the paper did not find this to be the case: "Surprisingly, we do not observe obvious patterns in the assignment of experts based on the topic." Instead it appeared that the experts seemed to be selected based on "structured syntactic behavior".
The exact role the structure plays in LLM generation is still in the early stages of exploration, but it increasingly appears to be a major component in the performance of these models and plays a much larger role than simply providing consistent format to the output.
Conclusion
Needing to provide only a single example of a problem to be solved provides a major advantage when working with LLMs. For many of the tasks that make a few shot classifier powerful, the fewer the shots required the better. Though LLMs are increasingly expanding their context length, for smaller (i.e. faster and more affordable) models it’s still important to limit the amount of context required for a given task for efficient inference. More important, for the kinds of problems where you only have a few labeled examples, there is often a major gap between having a single example and having multiple in terms of effort to build an application. Given the importance of structure to model performance, it increasingly appears that structured generation is a must have for anyone working with LLMs.