Say What You Mean: A Response to 'Let Me Speak Freely'
A recent paper from the research team at Appier, Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models, made some very serious accusations about the quality of LLM evaluation results when performing structured generation. Their (Tam, et al.) ultimate conclusion was:
Our study reveals that structured generation constraints significantly impact LLM performance across various tasks.
The source for this claim was three sets of evaluations they ran that purportedly showed worse performance for structured generation (”JSON-Mode” in the chart) compared with unstructured (”Natural Language”/NL in the chart). This chart (derived and rescaled from the original charts) shows the concerning performance:
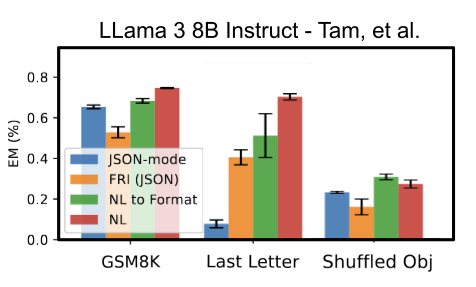
Figure 1: Original findings of Let Me Speak Freely
We here at .txt have always seen structured generation outperform unstructured generation in our past experiments. Our past experiments were on problems with clear, LLM-compatible structure, but so were the tasks that Tam, et al focused on (in fact, we had already done a similar experiment with GSM8K using different models). So these results from Tam, et al were as surprising as they were concerning.
After revisiting the above tasks with the same model (Llama-3-8B-instruct) we found that our results did not match those found in the paper, and reflected what we have previously seen. Diving deeper into the data and source code for the paper, we have determined there are several critical issues that led the authors to a fundamentally flawed conclusion.
More than a rebuttal, the goal of this article is to share some of the knowledge we have acquired by working daily with structured generation. We'll show where Tam, et al. made mistakes, but also provide insights into prompting for structured generation that should improve the response you get from LLMs even when you aren't using structured generation.
The Quick Rebuttal: Structured Generation improves performance.
For those needing a quick answer as to whether or not structured generation hurts performance: the answer is a clear no. In the figure below you can see the results of a quick implementation of JSON generation for all of the concerning eval runs in the article.
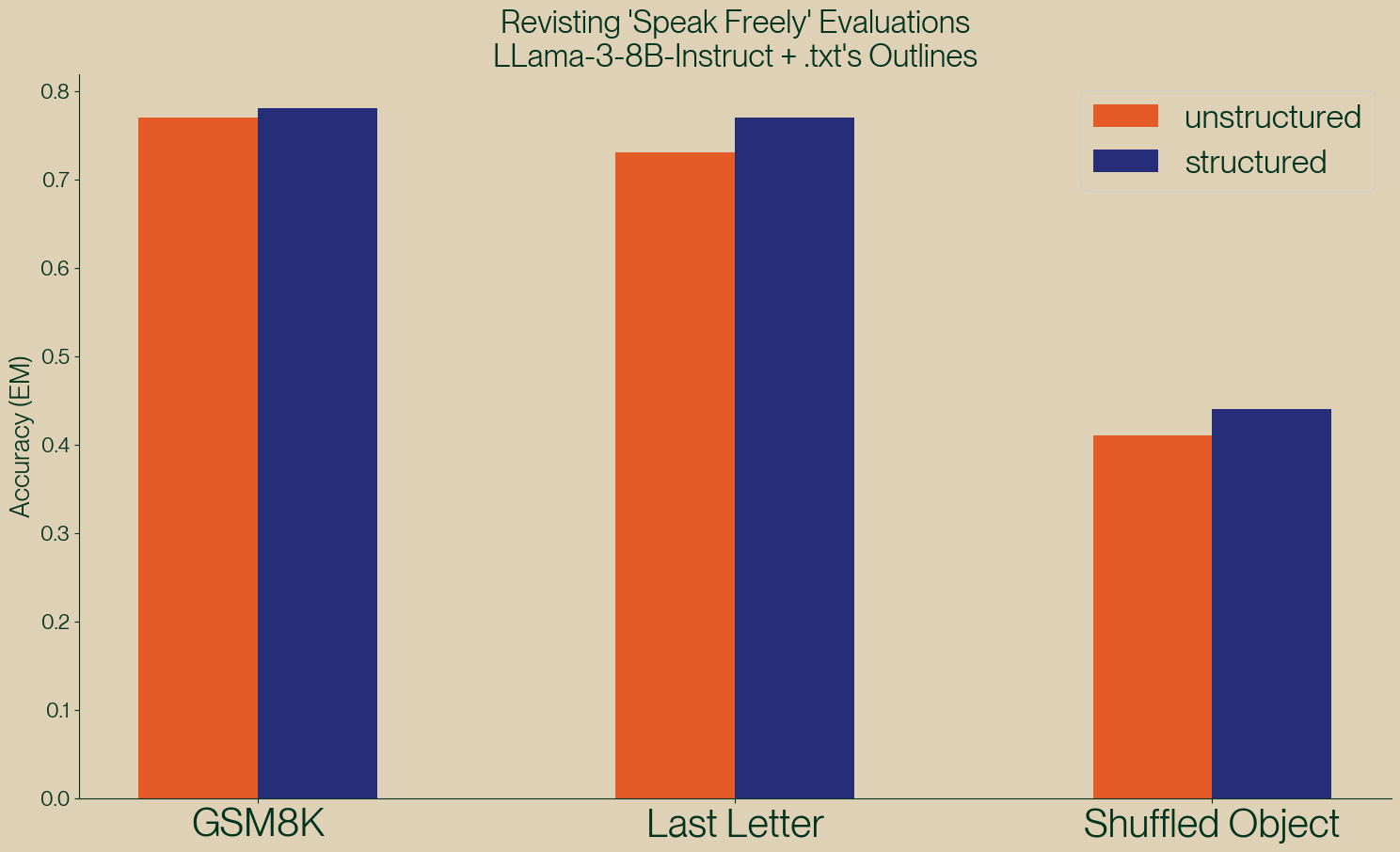
Figure 2: Results of re-implementing the concerning evals.
| Task | Unstructured | Structured |
|---|---|---|
| GSM8K | 0.77 | 0.78 |
| Last Letter | 0.73 | 0.77 |
| Shuffle Object | 0.41 | 0.44 |
While our unstructured results are in line with the paper, our structured results directly contradict the findings of the paper by showing that structured generation is an improvement across the board. Notebooks to reproduce these results can be found on github.
Here are some of the key issues we found in the paper:
- The paper itself finds that structured generation has superior performance on a number of classification tasks.
- The prompts used for unstructured (NL) generation are markedly different than the ones used for structured generation, so the comparisons are not apples-to-apples to begin with.
- The structured generation prompts do not provide the model with adequate information to solve the task, this leads to particularly poor performance for the ‘json-mode’ examples.
- The real meat of the paper is actually about parsing the results of one LLM with a second LLM. The authors refer to this as the “Perfect Text Parser”, we will refer to it as the “AI parser” (for reasons we'll clarify soon).
- The paper confuses structured generation with JSON-mode1, although independent runs of these evals show that “JSON-mode” yields better results than unstructured generation.
An apt analogy would be to programming language benchmarking: it would be easy to write a paper showing that Rust performs worse than Python simply by writting terrible Rust code. Any sensible readers of such a paper would quickly realize the results reflected the skills of the author much more than the capability of the tool. But it is genuinely challenging to write optimally performant code, just like it is difficult to ensure your evaluations are truly representative of the task you are trying to understand and measure.
All that said, this paper does provide a great opportunity to dive a bit deeper into what structured generation is and how to get the best performance out of it.
Task Overview - Last Letter
Here we’ll be focusing on the task that Speak Freely claimed structured generation did the most poorly on: Last Letter.
In this task the model is presented with a list of 4 names such as:
Ian Peter Bernard Stephen
And then the model must concatenate the last letter of each. The answer for that example would be: NRDN
The evaluation consists of 150 questions in the “test” set, and 350 in the "train" set. The paper uses only the 150 “test” question, so we will as well (though all findings here also hold for the full set).
Why Do We Need Structured Generation? Parsing Results!
One of the more interesting parts of the approach in the paper,
that honestly should have been the focus, is the so called “Perfect Text Parser” used to extract the answer from the initial model response.
Typically most evaluation frameworks use a simple,
clearly defined regular expression when parsing responses, however Tam, et al use claude-3-haiku-20240307 to parse
the response from the generated output of model.
This means that two models are actually used for each answer.
In the paper they refer to this as the “Perfect Text Parser”. It turns out the choice of the word "perfect" is a bit misleading,
so we’ll be referring to this as the “AI Parser”.
It’s important to note this non-standard method for transforming the response because the primary reason we use structured generation when working with LLMs it to guarantee the format of the response for easy parsing. That is, parsing and structured generation go hand-in-hand. While there are quite a few issues with this paper, the use of the AI parser is quite interesting and worth exploring in the context of structured generation. We’ll take a look at AI parsing vs structured generation, which will help us gain a stronger understanding of just how powerful structured generation is.
Issue #1: The AI Parser
To better understand the impact the AI Parser makes, we’ll take a deep dive into one of their recorded examples.
Thankfully, Tam, et al. did provide extensive data (12GB!) from their experiments.
These experiments are all sorted by the model and the prompt template used.
We’ll be taking a deep dive into the lasterletter-t3-f3 prompt template using meta-llama/Meta-Llama-3-8B-Instruct
specifically looking at the 1-shot example.
Let’s start by looking at what the prompt instructs the model to do in the best performing Natural Language (NL) format:
Follow the instruction to complete the task: String manipulation task: • Given: A sequence of words • Required: A new string made from the last letter of each word • Process: Think step by step to solve this challenge Note: Ensure you've read the question thoroughly before beginning. Instruct : Provide your output in the following text format: Answer: <think step by step>. The final answer is <answer>
Notice that the format of the response is explicitly described: The final answer is <answer>.
This means, if the model were to adhere to our prompt, we should be able to parse all answers with this simple regex:
answer_regex = r'answer is ([A-Za-z]{4})'
To see the impact of using the AI Parser we can iterate through the recorded results of the experiment
(found in the file text_llama-3-8b-instruct_shots_1.jsonl). To be clear,
we aren’t running any models right now, just seeing how different parsing methods impact the final score for an existing experiment.
We can immediately see there is a discrepancy between the strict regex parsing and the AI parsing:
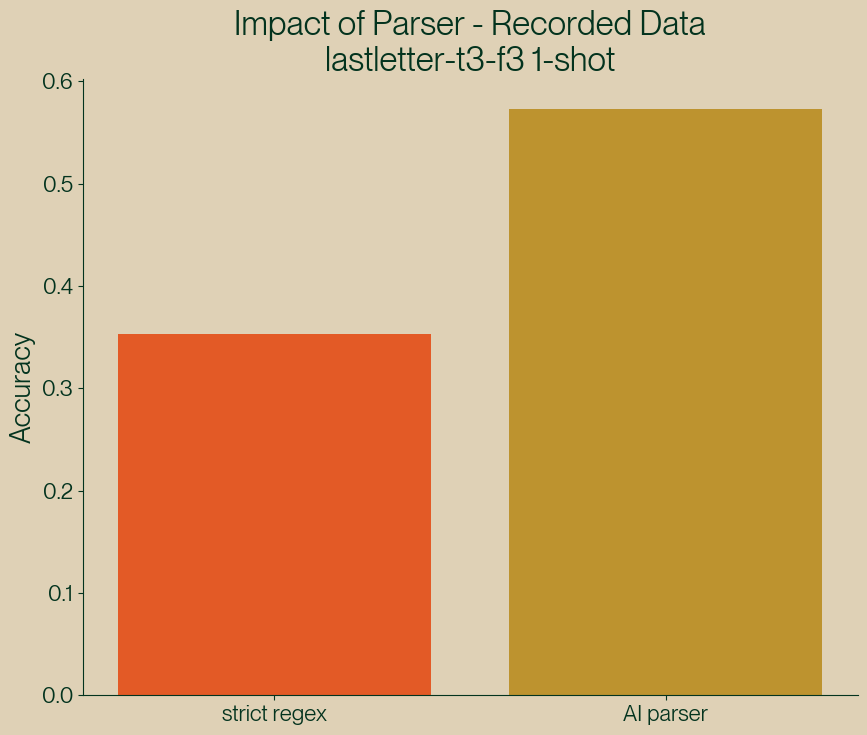
Figure 3: Comparing a strict regex parser with the AI parser.
So what’s happening here?
It turns out that AI parser is doing a lot of the heavy lifting for the NL format. By going over the results we can see there were many cases where our strict regex failed to capture the (arguably) correct response from the model. Here are a few examples that the AI Parser was able to correctly recover that didn't match our regex:
The answer is e-S-S-E.→ ESSEThe answer is AAA R.→ AAARThe answer is "reye".→ REYEThe final answer is: YOOI→ YOOI
Clearly our strict regex was indeed a bit too strict. All of these answers seem reasonable to me, there are a few cases in the full data set where one might disagree, but overall these seem acceptable responses. In lieu of an extra call to a more powerful model, a reasonable solution is to simply extend our regular expression so that it covers these cases. We’ll add the following alternate regexes to solve the sample cases we’ve found:
alt_regex_1 = r'answer is ([A-Za-z]-[A-Za-z]-[A-Za-z]-[A-Za-z])' alt_regex_2 = r'answer is:? "?([A-Za-z] ?[A-Za-z] ?[A-Za-z] ?[A-Za-z])"?' alt_regex_3 = r'Concatenating them is "([A-Za-z]{4})"' alt_regex_4 = r"answer is:? ([A-Za-z]'?[A-Za-z]'?[A-Za-z]'?[A-Za-z])"
It turns out that these cover the full set of cases we missed, no need for a separate model at all! If we use this combination of regexes we get the following results from parsing:
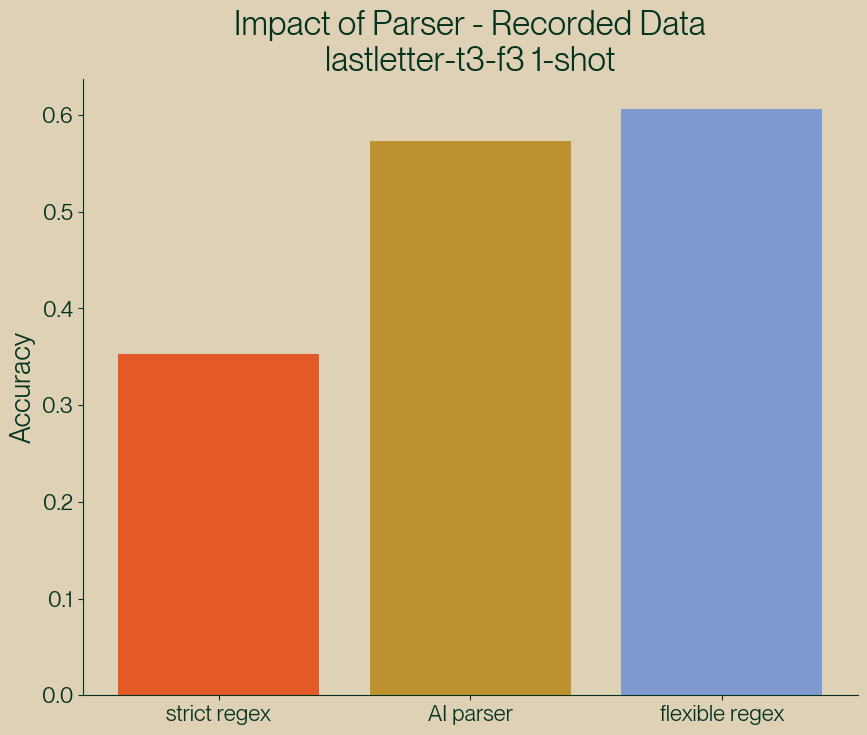
Figure 4: Comparing a strict regex parser, the AI parser and a more flexible regex parser.
| Parser | Accuracy |
|---|---|
| strict regex | 0.35 |
| AI parser | 0.57 |
| flexible regex | 0.61 |
Surprisingly, our hand curated list of regexes (which didn’t take too much time to write) outperforms the AI parser for this data set! It’s worth mentioning that the main selling point of structured generation is to not have to worry about this parsing. However it is a useful exercise that shows us that the AI parser is, in fact, not the “perfect” text parser: running our hand crafted flexible regex parser outperforms a call to Claude (and is much faster and cheaper!).
Reproducing These Results - Unstructured
Now let’s go ahead and run this using outlines.generate.text with the exact same prompt to see what we get.
We will make a small modification to the one-shot example used in the prompt.
Tam, et al’s examples only use two names, but all the questions use four.
In my experience, even without structured generation, it’s always important that your examples match the format you are looking for.
So we’ve modified the prompt example to include all four names.
When running using outlines.generate.text we get the following results compared to the original results reported in the data:
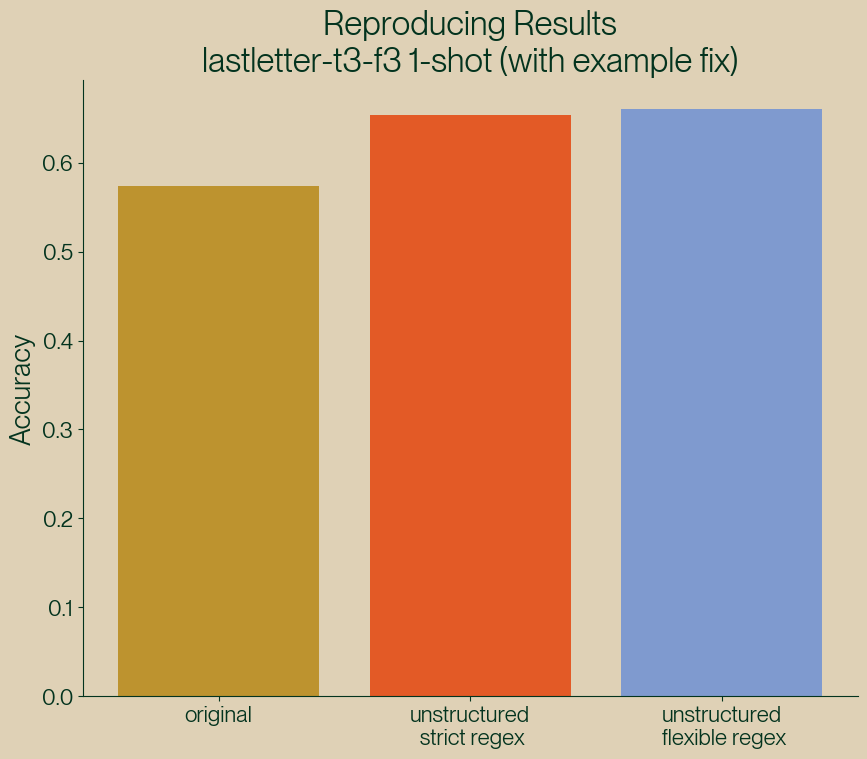
Figure 5: Reproducing the original NL results.
As you can see our results, while slightly better, are more or less in line with what the recorded results show. We’re also not aiming for perfect replication, just making sure our results are on the same page.
Since cleaning up the bad one-shot example, the gap in the difference between the parsers is also smaller. We’ve seen in the past that it seems what models are learning from the example cases is in fact the structure of the problem, so it’s not surprising that giving better examples of structure improves adherence to that structure.
Now we can really test the impact structured generation has on performance.
Anything You Can Parse, You Can Generate
The reason we focus on the AI parser is that understanding how you parse the response from an LLM is the key to really understanding structured generation. It’s a common misunderstanding (one made by the paper) to think that structured generation is merely another name for JSON-mode (or YAML-mode, XML-mode, etc). A better mental model for structured generation is: running our response parser as a generator.
To make this clear, when running structured generation on the prompt used, we are simply going to add structure for the reasoning step, and then append our answer regex to that. This allows a unification of the prompt, the parser, and the generator. That’s the secret to why structured generation is so powerful.
Let’s define our structure and see how it does. Here’s a regex that represents the “chain-of-thought” reasoning structure in the answer (which is also found in the prompt itself):
cot_regex = r'Answer: T[\w \\",\\.]{30,250}. The '
This will allow the model “think” for between 30 and 250 characters, then start it’s answer.
To complete our structure we just use our existing answer_regex to make our generator:
struct_strict = outlines.generate.regex(
model,
cot_regex + answer_regex,
sampler=greedy())
That’s it! We’re going to use our default strict regex because the entire point of structured generation is not to worry about parsing out output! There’s no need to use the more flexible regex since the model will only output what we want. Let’s see how it does:
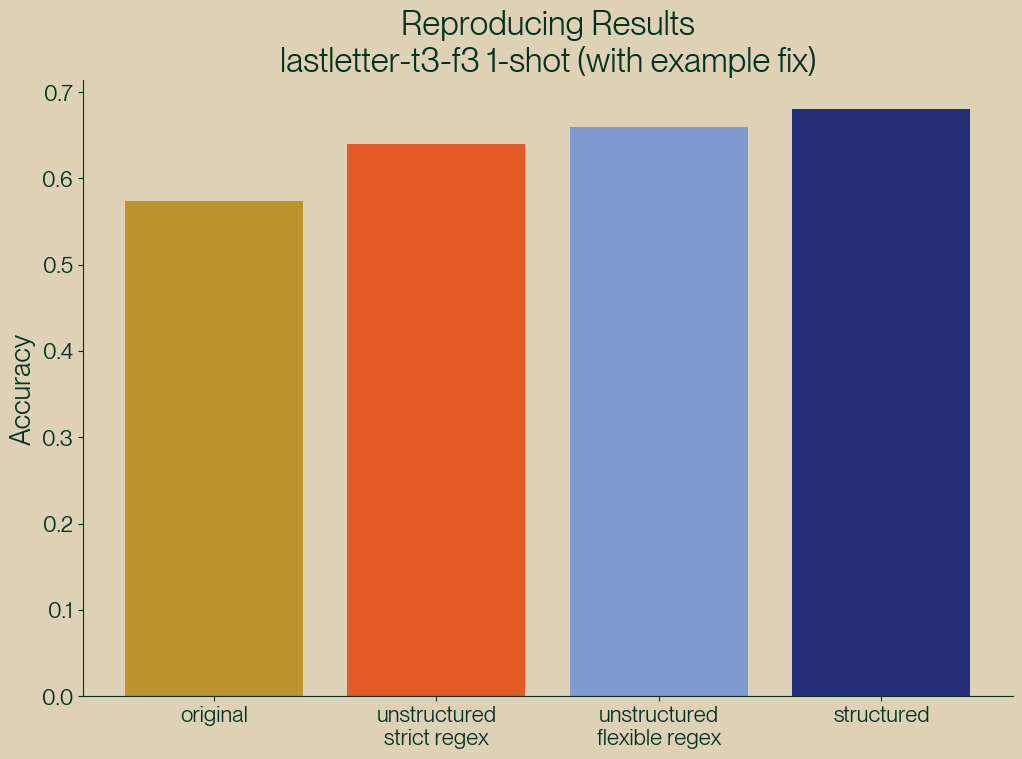
Figure 6: Reproducing the original NL results with structured generation.
| method | Accuracy |
|---|---|
| original | 0.57 |
| unstructured (strict) | 0.65 |
| unstructured (flexible) | 0.66 |
| structured | 0.68 |
Consistent with all of our past findings, structured generation outperforms unstructured generation.
What about JSON?
With some insight into how to properly perform structured generation, let’s try to figure out what went wrong with the JSON results. After all, if correct, the results in this chart are concerning:
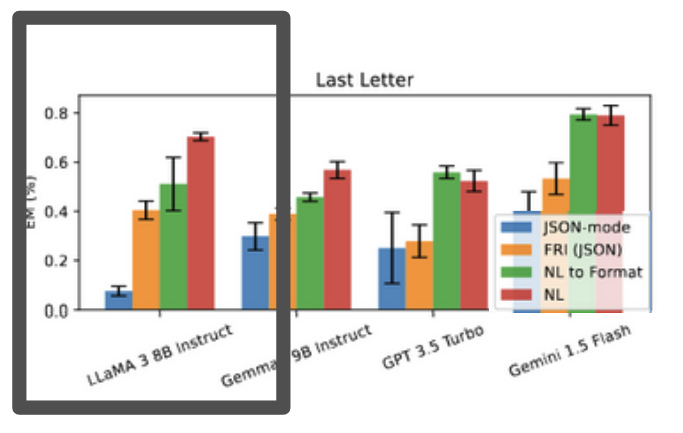
Figure 7: Original chart showing poor JSON-mode performance on Last Letter.
In the chart above, it looks like the structured generation (JSON-mode) is getting an awful < 10% accuracy compared to the unstructured (NL) result that’s getting ~70% accuracy. The NL result is essentially what we reproduced previously, so that result is in line with what we reproduced, but that 10% doesn’t match with what we saw. Maybe it’s an issue with requiring the model to respond in JSON?
Issue #2: Bad Prompting
As mentioned, a major issue with Speak Freely is that the paper uses different prompts for structured generation and unstructured generation. In our example, to evaluate the performance of structured generation, we compared results with the same prompt. This is the only honest way to make any statements about structured vs unstructured performance.
Because of this the first place we should look for trouble is in the prompt used for the JSON-mode evaluations.
So let’s take a look at the recorded data that matches closely to these results in the chart
(found in lastletter-t2-structure/struct_llama-3-8b-instruct_shots_0.jsonl). Here is an example of the prompt used:
Follow the instruction to complete the task: Read carefully for each of the last question and think step by step before answering. You are given a string of words and you need to take the last letter of each words and concate them Instruct : You must use the tool Question: Take the last letters of each words in "Britt Tamara Elvis Nayeli" and concatenate them.
This prompt needs substantial improvement before it can be used to properly evaluate the task at hand! One practice I encourage when writing prompts is to always ask yourself “does this prompt contain enough information that a reasonably well informed human could answer the question correctly?” Reading this prompt is not obvious to me that:
- The answer must be JSON (JSON isn’t mentioned at all)
- Even if you did guess JSON for the response, what is the schema you should respond in?
While tool use is mentioned, the prompt doesn’t mention the tools to use! There is no way an LLM could infer what it’s supposed to be doing. Structured generation is incredible, but it can’t magically make a model understand what you want any more than throwing rail road tracks in your backyard will make your home a convenient train stop.
Proper Prompting for JSON
We discussed earlier that structured generation is not the same thing as JSON-mode, but sometimes we do want JSON. To understand where Speak Freely went wrong, let’s walk through the way to do structured generation correctly. We’ll start by using an instruct prompt such as the following:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an expert in solving simple word puzzles using reasoning steps. Your specific
task is going to be to take a list of 4 names and reason about the last letter of each .,
then you will concatenate those letters into a word. The Question will be plaintest from the user
and response will be formatted as JSON below:
{"reasoning": <reasoning about the answer>, "answer": <final answer>}<|eot_id|><|start_header_id|>user<|end_header_id|>
Question: Take the last letters of each words in 'Ian Peter Bernard Stephen' and concatenate them.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{"reasoning": "The last letter of 'Ian' is 'N', the last letter of 'Peter' is 'R', the last letter of 'Bernard' is 'D', and the last letter of 'Stephen' is 'N'. Therefore, the answer is 'NRDN'.", "answer": "NRDN"}<|eot_id|><|start_header_id|>user<|end_header_id|>
Question: Take the last letters of each words in "Britt Tamara Elvis Nayeli" and concatenate them.",<|eot_id|><|start_header_id|>assistant<|end_header_id|>
<|eot_id|>
Here are a few things that make this prompt good.
- Using the proper instruct format for our model (using
apply_chat_template). - Provide an example that uses the correct structure and matches our problem.
- End with an empty “assistant” prompt so that the response will start with our structure.
Structured generation works perfectly well with continuation models,
but since we’re using an instruct model we should use the instruct prompt format for best results (this is issue 1).
The most important thing we’ve done is 2 which is to show the model the structure we want it to follow.
Item 3 is a small but important detail: instruct prompts are trained to alternate between the ‘user’ role and the ‘assistant’ role,
if we don’t start with the empty assistant response the model will want to start with assistant... rather than our desired structure
{"reasoning": ....
It can be quite helpful when writing your prompt to also generate unstructured samples to see how well the model is following the desired formatting behavior.
Defining Our Structure
Next we want to define our structure (though really this should go hand in hand with the prompt). For this task we’ll use a simple Pydantic model:
class Response(BaseModel): reasoning: constr(max_length=250) answer: str = Field(pattern=r'[A-Z]{4}')
We’re constraining the reasoning step here to 250 characters to make sure it doesn’t take too long to reason, and also constraining our answer to only valid possible responses of 4 letters.
A really important step in the process is to verify the prompt contains our structure. The entire point of the prompt is to prime our LLM for success, if we aren’t showing it the exact structure we want, the model will have to work harder to get the correct answer. Here’s the code for our ensuring the prompt matches the structure:
from outlines.fsm.json_schema import build_regex_from_schema schema_regex = build_regex_from_schema(Response.schema_json()) example_prompt = create_prompt(all_evals[5]['question'], tokenizer) re.search(schema_regex, example_prompt)
After verifying this we’re good to go! It’s worth pointing out that doing all these thing will also generally improve your unstructured results.
JSON Results
Now let’s run a proper apples-to-apples comparison of structured generation to unstructured. Here is the outcome of running this eval:
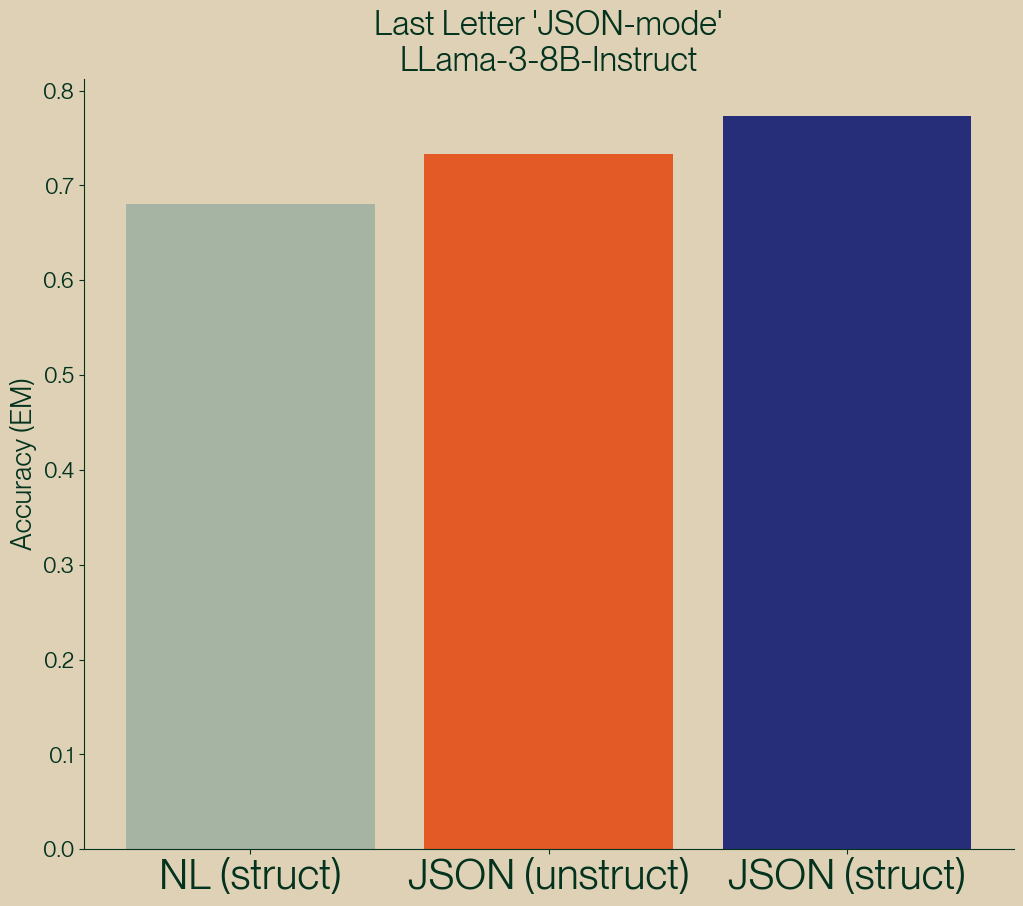
Figure 8: Results of comparing structured and unstrutured JSON generation using the same prompt (compared with NL structured prompt).
| method | Accuracy |
|---|---|
| NL (struct) | 0.68 |
| JSON (unstruct) | 0.73 |
| JSON (struct) | 0.77 |
Once again we see that structured generation outperforms unstructured generation. It’s also worth noting that our unstructured JSON result (at 73% accuracy) outperformed our structured natural language (68% accuracy) result, but our overall winner is structured JSON with 77% accuracy!
Here we can see why it’s essential to compare apples to apples when understanding the performance of structured generation. If, for example, we compared the JSON prompt for unstructured and the NL for structured, we would incorrectly conclude the structured generation is slightly worse, when the issue is really the prompt.
Conclusion
We here at .txt are passionate about structured generation, and truly believe it has the potential to transform the work being done with LLMs in profound ways. That’s precisely why we take claims that structure generation has adverse effects on LLM output very seriously. As a community we are all still learning how to get the most out of LLMs and working hard to advance this promising area of research. Everyone struggles at times to get LLMs to perform. If you are experiencing problems with structured generation, don’t hesitate to reach out. We would love to understand more about the areas where structured generation might need improvement, and get those areas fixed.
That is why it is so disappointing when other researchers take less care and end up spreading misinformation, that we then have to do the work to correct. If you’re interested in driving the future of LLMs, we’re more than happy to help you on your journey.
But, if you are going to publish a damning critique of structured generation, just make sure you put the same effort in to understanding the problem as we would. Or, perhaps better expressed by Omar Little from the Wire:
"Come at the King, you best not miss."
Footnotes:
"JSON-mode" refers to a fine-tuning process rather than strict structured generation. JSON mode has no guarantees about the returned value, highlighted briefly in our video on the topic.