Coding For Structured Generation with LLMs
We talk a lot here on the blog about what structured generation is capable of, but we haven't spent much time showing you how to write code for structured generation. In this post we're going to go through an example that shows not only how to use structured generation in your LLM code, but also gives an overview of the development process when working with structured generation. If you've been working with LLMs a lot, and focusing primarily on prompting, I think you'll be surprised how much writing structured generation code with LLMs feels like real engineering again.
For those new to the blog: structured generation using Outlines (and soon .txt's products!) allows us to control the tokens that an LLM samples from so that the output of an LLM always adheres to a specified regular expression. Structured generation can be performed at essentially no cost during inference (and can potentially speed up inference dramatically) and has consistently shown dramatic improvement in benchmark LLM performance.
To demonstrate how to write code for structured generation we'll be building a simple (but complex enough to be interesting) LLM program to generate synthetic data using Mistral-7B-v0.2-instruct. Our task will be to generate realistic looking phone numbers for Washington State. Using an LLM for this task is a bit overkill since we could just as easily accomplish this with a tool like Faker, but this example still serves as a useful way to explore structured generation with LLMs. It's also not hard to imagine this as the first step in a larger synthetic data generation project that could justify the use of an LLM.
The Unstructured Approach
Before diving into structured generation, let's first see how well the model performs by itself. For this case we'll prompt the model to generate an example phone number which conforms to a specific format. Then we'll call the model 10 times to generate 10 simulated phone numbers which we would presumably use as synthetic data for another process (maybe as testing data for a phone call processing application).
We'll begin by loading our model using Outlines.
import outlines model_name = 'mistralai/Mistral-7B-Instruct-v0.2' model = outlines.models.transformers(model_name)
Next we'll create our prompt.
We're using an 'instruct' or 'chat' interface to the model so it will be helpful to use HuggingFace's AutoTokenizer to generate the prompt from a list of messages.
This will ensure that our prompt is in the format the model expects.
We're going to keep our prompt simple and we won't be touching the prompt at all throughout the post. One of the major benefits that I have personally found of using structured generation is that I no longer have to spend time fiddling with my prompt in hopes of getting better performance.
Here is the code to create our prompt:
tokenizer = AutoTokenizer.from_pretrained(model_name) messages_phone = [ {"role": "user", "content": """ Please generate a realistic phone number for Washington State in the following format (555) 555-5555 """} ] prompt_phone = tokenizer.apply_chat_template(messages_phone, tokenize=False)
Now we're ready to sample! We can use Outlines to generate unstructured text just as
easily as we can for structured output:
phone_generator_unstruct = outlines.generate.text(model) for _ in range(10): print(phone_generator_unstruct(prompt_phone,max_tokens=12))
Here is the unstructured output:
I'd be happy to help you generate a realistic phone I cannot generate a real phone number as I'm just I'm an AI and don't have the ability Sure! Here is a randomly generated phone number in the format Here's a phone number that fits the format for a In Washington State, phone numbers typically have a three-dig Here are a few examples of phone numbers that could be considered I'd be happy to help generate a realistic phone number I'd be happy to help you generate a random phone Based on the format you provided, a realistic phone number for
Wow! These results are useless! What we see here is the model is "yapping" quite a bit. "Yapping" is a common problem where models struggle to get to the point and give you the result you want. As a consequence of this yapping, not a single one of these examples even has a phone number in the format we requested. If you've been working with LLMs long enough you likely already have ideas for changes to the prompt you could make to help. But you know as well as I do, that approach is going to involve countless iterations each with questionable success.
Instead let's leave that prompt alone and go down the path of structured generation!
The Structured Generation Development Loop
If you've worked with LLMs before, you likely have spent a lot of time "prompt hacking". Working with structured generation you'll quickly find that you can get better results while mostly ignoring the details of the prompt. Working with non-trivial structured generation involves a pattern of iterating on your structure until you get the model to behave exactly as you expect.
Here is a diagram of the standard structured generation development workflow:
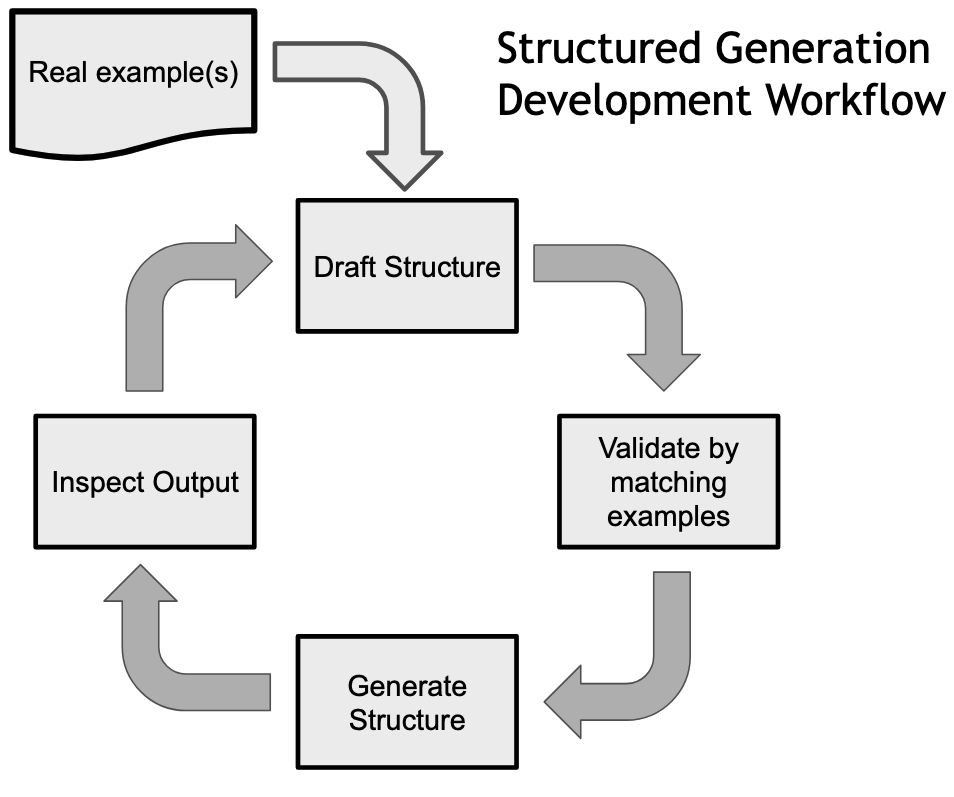
To understand this better we'll walk through several iterations of this and ultimately be able to generate an ideal set of synthetic telephone number data.
Start with Real Data
The aim of writing structured generation is to get our LLM to consistently output text in the correct format. In our case we want our model to output phone numbers for the Seattle area (technically anywhere in the state of Washington) that look like this:
(XXX) XXX-XXXX
It's easy to imagine what we would like output to look like. Writing code for structured generation is about precisely encoding that image in our minds into a form of structure (typically a regular expression). To do this we need to look at some real data first. For this simple example we'll use a real phone number, the number for the Seattle public library:
phone_number = "(206) 386-4636"
For more complicated cases it can help to have more examples, but the basic logic we'll apply to this single case is easy to scale up if necessary.
Now that we have an example of what we want our output to look like we'll start by writing a regex that matches this example. Note that even though our goal is generation we start by simply seeing if we can match the data we know is correct.
First Attempt at Structure
Writing regular expression is not easy, especially if it's been awhile. That's okay because the process we'll be following makes it easy to debug and iteratively improve our regexes. It's worth noting, because of how much the LLM was "yapping" in our unstructured case, we'd need to build a regex anyway to be able to parse the output after the model had yapped enough to finally produce the number we wanted.
Let's start with a simple regex that should match our phone number:
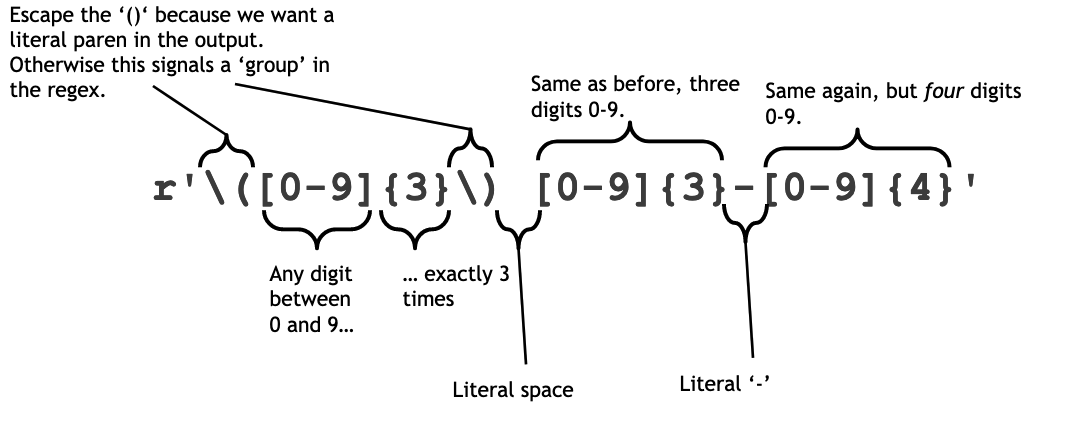
phone_regex_1 = r'\([0-9]{3}\) [0-9]{3}-[0-9]{4}'
In case you are a bit rusty on regular expressions, here's a visualization of what this one is doing:
Next we need to verify that this regex does what we think it does.
Validating Structure on the Real Data
Even though we'll be using structured generation to generate data based on a regular expression, we first
want to make sure that our regex actually matches the data we know to be correct. We start by simply calling
re.match on our data with the our first draft of a regex and making sure it matches:
import re re.match(phone_regex_1, phone_number) # <re.Match object; span=(0, 14), match='(206) 386-4636'>
As we can see the regex and our example data successfully match! This doesn't mean we're done, but it does help us to verify we're on the right track. The fact that structured generation allows us to essentially "run a regular expression in reverse" unlocks a very powerful debugging tool since we can always apply our structure for generation to real data to make sure we're generating what we think we are.
Inspecting our Structured Generation
Now that we have a regex and validated that it matches our real data, we're ready to generate our first set of 10 example phone numbers. The code is surprisingly simple:
phone_generator_v1 = outlines.generate.regex(model, phone_regex_1) for _ in range(10): print(phone_generator_v1(prompt_phone))
Here is the output from our first version of structured generation:
(206) 555-1234 (206) 555-1234 (206) 555-1234 (206) 555-1234 (206) 555-1234 (206) 555-1234 (206) 123-4567 (206) 555-1234 (206) 555-1234 (206) 555-1234
This time we have phone numbers, and the model did something else impressive: 206 is the correct area code for Seattle Washington. This demonstrates a great example that structured generation does not get in the way of what models do well. We could have specifically encoded the correct set of area codes into the structure (and if we found bugs in the future we still might!), but we don't have to. When left to its own devices the model couldn't produce correctly formated output, but with structure the model is capable of figuring out the correct area code.
Unfortunately these results are pretty boring. We have 9 cases of the same number and all of the numbers feel very artificial.
If you've been writing code for LLMs for awhile I bet there are two solutions that immediately came to your mind:
- Prompt hacking: "We just need to add instructions to the prompt to make the results more 'creative'!"
- Sampler tweaking: "We just need to change the temperature parameter and the results might be better!"
While either of these techniques might work, the problem is we're venturing quickly out of "engineering" territory and deeper into a world where we have increasingly less control over the behavior of our model. Adding solutions like these increasingly makes our LLM based software products more fragile and harder to debug and improve in the future.
Let's continue with our structured development loop and iterate to see if we can improve these results.
Iterating on our Structure
Okay, so our results aren't good, let's revisit our structure and see how we might be able to fix this. One obvious problem is that '555' appears in almost all cases. This is likely the case because most examples of phone numbers in the data used to train the model use the fake '555' series of numbers so that real people aren't actually called. So even with random sampling we're still very likely to choose '555' as the start of the number.
We can solve this simply by disallowing the model to use '5' at all in this first three number sequence.
Additionally '1234' appears frequently in the last 4. We'll can solve this by making sure the first of these last four numbers is not 1.
Here is a revised version of our regex:
phone_regex_2 = r'\([0-9]{3}\) [2-46-9]{3}-[02-9]{4}'
You might be tempted to immediately rerun our generation step with this new regex. I highly discourage this as it can easily lead to bugs in your structure that you haven't caught. Instead, we should always verify our new structure on our original data.
Because we're adding sophistication to our structure, let's add a bit of sophistication to our verification. In addition to checking whether or not our regex matches, we can also compare the portion of the string that matches with the example phone number.:
re.match(phone_regex_2, phone_number)[0] == phone_number # True
We see this does exactly match our original example phone number, so let's try generating again with our new structure!
phone_generator_v2 = outlines.generate.regex(model, phone_regex_2) for _ in range(10): print(phone_generator_v2(prompt_phone))
Here is the output for our second version of structured generation:
(206) 867-5309 (206) 666-7777 (206) 444-3333 (206) 444-3333 (206) 943-2222 (206) 323-6789 (206) 444-3333 (206) 867-5309 (206) 466-2255 (206) 222-3333
This is certainly an improvement, but I'm personally still not impressed. I want synthetic data that looks more interesting, and here we have a lot of repeated sequences of digits.
While these all match our regex and are likely valid numbers, I want to capture something aethestic about the structure here. I want these numbers to feel more "random". Let's continue and iterate one more time.
Debugging Our Structure
Our goal is to make these numbers "feel" a bit more unique. When people first encounter structured generation they typically think of things like generating JSON or YAML, that is, doing things that have a very clear format. But it turns out structure is everywhere. We can use structure to make the output of our LLMs feel nicer, rather than just be formatted correctly.
We're going to modify our preview regex again so that it's more complex, but should capture the feel we want better.
Here's a first pass at this:
phone_regex_3_error = r'\([0-9]{3}\) [2-4][7-9][4-6]-[3-6][2-8][1-4]'
If you quickly look at that regex, you'll likely think it looks good. When writing this demo I thought it looked correct at first pass too! But, as the variable name implies, there is a stubtle error here.
Let's run out matcher again to verify this is correct. We'll also build out our checker a bit more to make it a more helpful debugger:
if not re.match(phone_regex_3_error, phone_number): print("Regex fails match") else: matched_string = re.match(phone_regex_3_error, phone_number)[0] if matched_string == phone_number: print("Successful match") else: print(f"Error {matched_string} != {phone_number}") # Error (206) 386-463 != (206) 386-4636
Our regex matches, but it was not a complete match! We forgot the last digit!
With structured generation the LLM will always produce exactly what we ask it to, but this means we have to be clear about what we're asking it to generate.
Because structured generation is about modifying deterministic structure, not fiddling with non-deterministic prompting or temperature parameters, we are able to really debug our LLMs! If you've been an AI Engineer for awhile this bit of troubleshooting should feel incredibly refreshing.
Let's add our fix, and rerun to see how we like the results:
phone_regex_3_fixed = r'\([0-9]{3}\) [2-4][7-9][4-6]-[3-6][2-8][1-4][6-9]' phone_generator_v3 = outlines.generate.regex(model, phone_regex_3_fixed) for _ in range(10): print(phone_generator_v3(prompt_phone))
Here is the output at our third pass at structured generation:
(206) 494-3216 (206) 374-6218 (206) 494-3337 (206) 476-3216 (206) 484-3548 (206) 495-3218 (206) 494-5517 (206) 375-4636 (206) 384-6216 (206) 385-6218
These results are much closer to what I was imagining when we started this task.
All of our numbers are different and they all pass the vibe check for me in that they feel like they could be real.
Software Engineering for LLMs
While this example is fairly simple it reflects the real development experience I've personally had in much larger projects, like replicating function calling behavior in LLMs and beating GPT-4 at function calling. What's incredible about this process is we didn't have to "prompt-and-pray" by fidgeting with arbitrary changes to the prompt and hoping for good results.
This is hugely important for two major reasons.
First and foremost, it means AI Engineers can be Software Engineers again! In this example we wrote a working LLM program that progressively improved and was easy to debug. When working with prompts directly it's hard to tell what's wrong and even harder to tell if you've really fixed the problem. The same goes for tweaks with the sampler or temperature parameter.
Which brings up the second point: improvements brought on by prompting are often illusory. In my time working with LLM based products, I often had seen cases where prompt hacks seemed to work on a few examples. For many teams this initial "vibe check" is all that is done to verify a fix. However, I often found that when running these prompt hacks against a full suite of evals there would be no notable improvement, or even a decline in performance!
Structured generation is more than just JSON, it's essential for being able to build reliable and scalable software systems around LLMs.
In our next post we'll take a look at a more ambitious project: implementing function calling for open LLMs using structured generation with Outlines. Subscribe below to be notified when that's released!